
机器学习
机器学习的定义
(非正式定义)Arthur Samuel:
在不直接针对问题进行编程的情况下,赋予计算机学习能力的一个研究领域。
在机器学习的历史上,Arthur Samuel做了一些非常酷的事情。他曾经做了一个西洋棋程序,让计算机自己跟自己下棋,下棋速度非常快,因此Arthur Samuel让他的程序自己和自己下了成千上万盘棋,逐渐的,程序开始慢慢意识到怎样的局势能导致胜利,怎样的局势能导致失败,因此它反复的自己学习“如果让竞争对手的棋子占据了这些地方,那么我输的概率可能更大”或者“如果我的棋子占据了这些地方,那么我赢的概率可能更大”所以渐渐的,Arthur Samuel的程序掌握了哪些局面可能会输,哪些局面可能会赢,因此奇迹出现了,他的程序的棋艺甚至远远超过了他自己。ArthurSamuel让他的程序比他自己更会下棋,但是他并没有明确的教给程序具体应该怎么下,而是让它自学成材。
(现代化定义)Tom Mitchell:
对于一个计算机程序来说,给它一个任务T和一个性能评测方法P,如果在经验E的影响下,P对T的测量结果得到了改进,那么就说明程序从中学习到了经验E。
对于西洋棋的例子来说:
- E - 程序成千上万次的自我练习
- T - 下棋的任务
- P - 程序将赢得下一场比赛的概率
机器学习分类
机器学习分为
- 监督学习
- 无监督学习
- 半监督学习
- 强化学习
监督学习
什么是监督学习?
监督式学习是一个机器学习中的方法,可以由训练资料中学到或建立一个模型(函数),并依此模式推测新的实例。训练资料是由输入物件(通常是向量)和预期输出所组成。函数的输出可以是一个连续的值(称为回归分析),或是预测一个分类标签(称作分类)
监督学习的分类
监督学习分为回归问题和分类问题
- 回归问题-给定的一个房子面积来预测这个房子在市场中的价格。
- 分类问题-给定一个肿瘤的大小来预测它是良性还是恶性。
无监督学习
什么是无监督学习?
给定的一个数据集,无监督学习算法可以将数据分成两个簇,将数据分成不同簇的无监督学习算法也被称作聚类算法。
无监督学习的分类
- 聚类-根据给定的基因将人群分类
- 非聚类-鸡尾酒派对效应
单变量线性回归模型
训练集
由训练组成的集合就是训练集,
回归模型常用符号
- m-训练样本的数目。
- x-表示输入变量(特征量)。
- y-表示输入出的变量(目标变量)。
- (x,y)-表示一个训练样本(表格中单独的一行对应于一个训练样本)。
- -表示第i个训练样本(这里的i不是表示幂运算,而是代表上标)。
- h-表示一个假设函数,h根据输入的x值来得出y值,所以可以说h是从x到y的函数映射。
graph TD
A(训练集)-->B(学习算法)
B-->C(假设函数)
假设函数
我们使用如下形式表示假设函数,为了方便$h_\theta(x)$也可以记作$h(x)$。
以上模型就叫做单变量线性回归。
- -模型参数。
假设函数中有两个未知的变量,。当选择不同的和时,我们模型的效果肯定是不一样的。
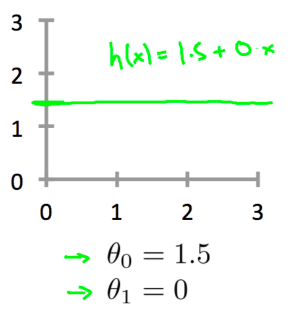
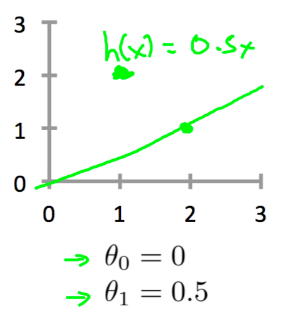
代价函数
我们需要选择某个和,使得对于训练样例,最接近。越是接近,代表这个假设函数越是准确,这里我们选择均方差来作为衡量标准,即我们想要每个样例的估计值与真实值之间差的平方的均值最小。用公式表达为:
为了方便计算,我们记为:
这样就得到了我们的代价函数,也就是我们的优化目标,我们想要代价函数最小: